
Creación del Plan de Gestión de Datos
Los Planes de Gestión de Datos (PGD) son elementos imprescindibles para asegurar una correcta gestión de los datos de investigación. Además, también se está convirtiendo en un requisito para optar a financiación de proyectos de investigación, por ejemplo:
-
Desde enero de 2017, en los proyectos del H2020 se debe realizar un PGD que se actualizará a lo largo del proyecto
-
Se debe redactar un PGD en los Proyectos I+D+i correspondientes a la convocatoria del año 2020 de ayudas del Plan Estatal de Investigación Científica y Técnica y de Innovación 2017-2020
Un PGD describe el ciclo de vida de la gestión de los datos en la utilización, procesamiento y generación para conseguir que los datos de investigación sean localizables, accesibles, interoperables y reutilizables, es decir, que sean FAIR (Findable, Accesible, Interoperable and Reusable). En resumen, indica qué se va a hacer con los datos durante y después de finalizar la investigación.
Un PGD debe incluir información sobre:
-
Determinar los requisitos de la entidad financiadora
-
Identificar los datos que se utilizarán: tipología, procedencia, formatos, etc.
-
Definir cómo se organizarán y gestionarán los datos: control de versiones, nombre de ficheros, etc.
-
Explicar cómo se documentarán los datos
-
Describir cómo se asegura la calidad de los datos
-
Preparar una estrategia de almacenamiento y preservación de los datos
-
Definir las políticas de datos del proyecto: propiedad intelectual, tratamiento de datos sensibles y personales, etc.
-
Describir cómo se difundirán los datos: dónde, cuáles y cuándo se van a difundir, etc.
-
Asignar roles y responsabilidades
-
Preparar un presupuesto realista para la gestión de los datos

Fuente: REBIUN. 10 pasos para elaborar un Plan de Gestión de Datos ![]()
En las pestañas de la parte superior se muestran plantillas, herramientas y ejemplos para facilitar la creación de un PGD, como la guía para la elaboración de un PGD en el contexto de la UPV
El Digital Curation Center (DCC) ha publicado el Checklist for a Data Management Plan que facilita la realización de un Plan de Gestión de Datos (PGD)
Por otra parte, Science Europe ha publicado la Practical Guide to the International Alignment of Research Data que proporciona una guía para redactar un PGD. Además, tiene un capítulo dedicado a la evaluación del PGD, que puede ser utilizado tanto por revisores como por los propios investigadores como una herramienta para la autoevaluación del PGD
De forma más específica, se ha desarrollado una guía para la elaboración de un PGD en el contexto de la UPV. Esta guía, basada en la realizada por Science Europe, pretende:
-
Mostrar los diferentes aspectos que debe tener un PGD
-
Ayudar a entender y facilitar la respuesta a las cuestiones que se plantean
-
Dar a conocer los diferentes servicios que ofrece la UPV que están relacionados con la gestión de los datos de investigación
También existen varias recomendaciones y guías para la creación de un PGD enfocado al mandato del H2020
Argos es una herramienta online desarrollada por OpenAIRE para la creación, gestión, difusión y enlace de un PGD, que hace énfasis en la aplicación de los principios FAIR y en las mejores prácticas para fomentar la accesibilidad a los datos de investigación. Éstas son algunas de sus características:
-
Asistente para la creación del PGD en función del financiador
-
Asistente para la descripción de los datos de investigación, de manera que permite reutilizarlos en diferentes PGDs
-
Asignación de un DOI para el PGD si se publica, por lo que se facilita la visibilidad y citación del propio PGD
-
Exportación del PGD en formatos comprensibles por máquinas (xml, json) y por personas
-
Servicio incluido en el European Open Science Cloud (EOSC), iniciativa promovida por la Comisión Europea
Se puede encontrar más información sobre Argos consultando el manual de usuario o las FAQs

DMPonline es una herramienta online desarrollada por el Digital Curation Centre que facilita la creación, revisión y difusión del PGD. Éstas son algunas de sus características:
-
Permite trabajar en el PGD de forma colaborativa entre varios investigadores
-
Creación de PGD a partir de plantillas específicas para diferentes agencias de financiación (H2020, Wellcome Trust, etc.)
-
Se proporciona información que ayuda a cumplimentar cada uno de los apartados del PGD
-
Descarga del PGD en formato PDF para poder adjuntarlo en propuestas de financiación

A continuación, se muestran varios ejemplos de PGD:
-
Digital Curation Center (DCC): ejemplos de PGD siguiendo las indicaciones de diferentes agencias de financiación (H2020, Wellcome Trust, etc.)
-
DMPonline: ejemplos de PGD públicos depositados en la herramienta DMPonline
- DMP Catalogue: ejemplos de PGD organizados por temáticas. Cada PGD ha sido revisado por un grupo de trabajo de LIBER para indicar las fortalezas y debilidades de cada PGD
Trabajar con los datos
Cada vez existen más políticas y mandatos de agencias de financiación, instituciones y revistas que obligan o recomiendan el depósito en acceso abierto de los datos de investigación en repositorios de datos. La localización y reutilización de estos datos presenta múltiples beneficios
Existen diferentes herramientas para encontrar de datos de investigación que pueden ser reutilizados:
-
Dimensions: contiene más de 8 millones de datasets de Figshare, Dryad, Zenodo, Pangaea, Mendeley y más de 900 repositorios de DataCite
-
DataCite: proporciona una interfaz donde es posible buscar, filtrar y extraer información sobre miles de datos de investigación
-
Scholexplorer: recolecta información sobre datos de investigación a partir de diversas fuentes como CrossRef, DataCite y OpenAIRE. En muchos casos enlaza los datos de investigación con las publicaciones científicas que han usado estos datos
-
Google Dataset Search: ofrece datos de investigación de diferentes fuentes. Es posible filtrar los resultados por derechos de uso, formato de descarga, etc.
-
Directorios de repositorios de datos: permiten localizar repositorios de datos temáticos o multidisciplinares. Por ejemplo, re3data.org y Fairsharing.org
-
EUDAT B2FIND: herramienta de descubrimiento que da acceso a los datos de investigación depositados, entre otros, en EUDAT B2SHARE
-
Mendeley Data: proporciona acceso a datos de investigación publicados en repositorios de datos como Dryad o Zenodo y también en publicaciones de la editorial Elsevier
El nombre y la estructura de los ficheros que contienen los datos de investigación facilitan la comprensión y futuro uso de los datos. Por ello, se pueden seguir las siguientes recomendaciones:
-
Realizar una estructura jerárquica sencilla de comprender, con directorios que agrupen los ficheros de datos
-
Utilizar un sistema descriptivo y consistente que se seguirá para nombrar todos los ficheros
-
No utilizar nombres de ficheros demasiado largos, ya que pueden existir problemas con determinados programas
-
Evitar el uso de caracteres especiales ~ ¡ ! @ # $ % ^ & * ( ) ` ; < > ¿ ? , [ ] { } ' " |
-
Evitar el uso del espacio en blanco, en su lugar es mejor usar el guion bajo _
-
Para registros que tienen varias versiones, es aconsejable marcar al final del nombre el número de versión, por ejemplo, v01, v02, etc. Para la versión final se puede finalizar el nombre del fichero con el texto FINAL
Existen herramientas que permiten renombrar en bloque múltiples ficheros:
-
Bulk Rename Utility (Windows)
-
Renamer 6 (Mac)
Es recomendable utilizar formatos abiertos en los ficheros que contienen los datos de investigación para así asegurar que la mayoría del software sea capaz de interpretar los datos contenidos. De todas formas, no hay que olvidar que existen disciplinas que utilizan ciertos formatos propietarios de forma generalizada
A continuación, se muestran una serie de formatos de ficheros recomendados en función del tipo de datos que contiene:
-
Bases de datos: XML, CSV
-
Texto: RFT, TXT, XML
-
Estadísticas: ASCII, DTA, POR, SAS, SAV
-
Datos tabulados: CSV, TSV
-
Geospaciales: SHP, DBF, GeoTIFF, NetCDF
-
Vídeo: OGG, MP4
-
Sonido: FLAC, WAV, AIFF, MP3
-
Imágenes: TIFF, BMP
-
Ficheros comprimidos: no se recomienda el uso de ficheros comprimidos
Para más información sobre formatos recomendados en ficheros que contienen datos de investigación se puede consultar el UK Data Service
Como los formatos de ficheros con tabulados (CSV, TSV, XLS, XLSX, etc.) son unos de los más habituales que contienen datos de investigación, la Iniciativa de datos abiertos del Gobierno de España (datos.gob.es) ha elaborado una Guía práctica para la publicación de datos tabulares en archivos CSV

Fuente: Secretaría de Estado de Digitalización e Inteligencia Artificial del Ministerio de Asuntos Económicos y Transformación Digital. https://datos.gob.es/sites/default/files/doc/file/cheat_sheet_csv_vf.pdf
El formato de los ficheros que contienen los datos de investigación resulta fundamental para su futura reutilización. Tim Berners-Lee, el creador de la Web, propuso un esquema de 5 estrellas para clasificar los formatos de los ficheros en función de su grado de apertura, dando además una serie de beneficios que se alcanzan en cada una de las estrellas:
1 estrella: publica tus datos en la Web (con cualquier formato) y bajo una licencia abierta
2 estrellas: publícalos como datos estructurados, por ejemplo, Excel en vez de una imagen de una tabla escaneada
3 estrellas: usa formatos no propietarios, por ejemplo, CSV en vez de Excel
4 estrellas: usa URIs para identificar cosas, así la gente puede apuntar a estas, una forma de representar los datos es utilizar RDF
5 estrellas: enlaza tus datos a otros datos para proveerlos de contexto, facilitando la reutilización y optimizando las búsquedas
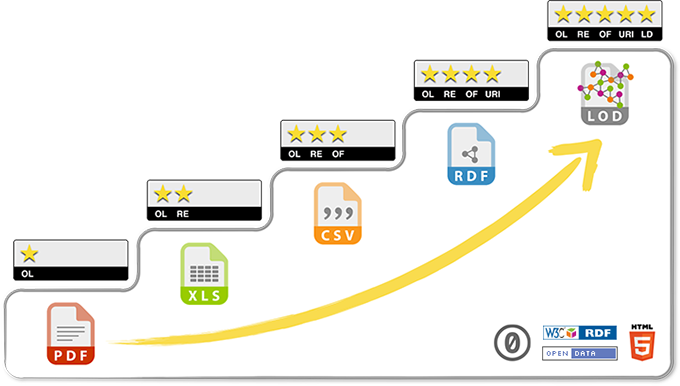
Fuente: https://5stardata.info/es/
Para una correcta compresión y utilización de los datos de investigación, se recomienda que se cree un fichero llamado “README” en formato txt. Dicho fichero estará ubicado junto con el resto de ficheros que contienen los datos de investigación y contendrá la siguiente información (en inglés):
-
Información general:
-
Título del dataset
-
Nombre, afiliación, dirección y email del investigador principal y los coautores
-
Fecha de creación y localización de los datos
-
Información sobre fuentes de financiación
-
Breve descripción del conjunto de datos
-
Palabras clave
-
-
Licencias y restricciones de uso de los datos
-
Información sobre los archivos: nombre y descripción de los archivos, versión, tamaño del conjunto de datos, etc.
-
Información sobre la metodología: descripción de la metodología para la creación y procesamiento de los datos
-
Información específica sobre los datos:
-
Listado de variables: nombres completos y encabezamientos en las columnas para datos tabulados
-
Unidades de medida
-
Definición de códigos o símbolos usados para registrar datos faltantes
-
Para facilitar la creación del fichero README se ha creado una plantilla a partir de la realizada por la Universidad de Cornell
Los datos de investigación deben cumplir con los principios FAIR (Findable, Accesible, Interoperable, Reusable), por lo que resulta imprescindible adjuntar a los datos de investigación, los metadatos que los describen de una forma completa y normalizada
Normalmente cada disciplina académica tiene iniciativas donde se describen los esquemas de metadatos que deben ser utilizados para una correcta descripción, interpretación y reutilización de los datos de investigación. En el caso de que no existan esquemas de metadatos específicos para una disciplina, también se pueden usar otros esquemas genéricos de datos de investigación
Además de los esquemas de metadatos, en muchos casos se han desarrollado herramientas que facilitan la creación y/o captura de metadatos para cada esquema de metadatos
El Digital Curation Center (DCC) dispone de un directorio sobre metadatos para datos de investigación con las siguientes características:
-
Esquemas de metadatos por disciplina académica: biología, ciencias de la tierra, ciencias sociales y humanidades, física y multidisciplinares
-
Perfiles y extensiones: esquemas que han sido adaptados para el uso de tipos de datos específicos o para el uso en determinados tipos de repositorios
-
Casos de uso: especificaciones de los metadatos que deben depositarse en determinados repositorios de datos
-
Herramientas: programas desarrollados para la captura o almacenamiento de metadatos de un determinado esquema
A lo largo de cualquier investigación se van generando documentos que se crean y modifican por una o varias personas. Esto hace que se generen diferentes versiones de un mismo documento. Si las versiones no se gestionan correctamente, pueden producirse situaciones negativas: pérdida de datos, replicación de trabajos, pérdida de tiempo, etc.
Para afrontar estos problemas, siguiendo las recomendaciones de OpenAIRE, existen varias soluciones que van desde un nombrado normalizado de los ficheros hasta la utilización de sistemas de control de versiones
Los sistemas de control de versiones, especialmente utilizados en el desarrollo de software, presentan varias características:
-
Trabajar con versiones en desarrollo
-
Mantenimiento de versiones estables
-
Participación de diferentes personas de forma concurrente
-
Detectar cambios realizados en las diferentes versiones, así como quién y cuándo se realizaron
-
Documentación en las versiones
El funcionamiento básico de estos sistemas es:
-
Código estable ubicado en un repositorio
-
Creación de una copia del código desde el repositorio al equipo local
-
Desarrollo y testeo del nuevo código en el equipo local
-
Subida al repositorio desde el equipo local del nuevo código estable
-
Fusión en el repositorio de la versión original del código y la nueva versión estable, registrando los cambios producidos
Existen diferentes herramientas para el control de versiones, entre las que destacan:
-
Subversion (SVN): sistema centralizado en el que todos los ficheros y los datos históricos son almacenados en un repositorio central y en el que los desarrolladores suben los cambios a este servidor
-
GIT: sistema distribuido en el que existe un repositorio central y copias de este repositorio en los diferentes equipos locales de los desarrolladores
Para más información sobre la utilización de sistemas de control de versiones se recomienda contactar con el ASIC
Durante el proceso de investigación se recopilan, generan y tratan múltiples datos que serán fundamentales para la investigación. Un almacenamiento incorrecto de estos datos puede provocar que se pierdan de forma permanente, lo que implica múltiples consecuencias negativas
Siguiendo las recomendaciones de OpenAIRE, la UPV ofrece a su comunidad universitaria dos servicios gratuitos para almacenar los datos de investigación de forma segura:
Discos para grupos
-
Posibilidad de que varios investigadores compartan el mismo disco virtual
-
Almacenamiento de 2 GB por persona, ampliable hasta 30 GB previa solicitud en la intranet (Herramientas > Utilidades > Gestión de cuotas). Si se necesita una capacidad de almacenamiento superior a 30 GB debe solicitarse vía Gregal
-
Acceso al disco virtual desde un dispositivo situado:
-
Dentro de la UPV: se conecta como una unidad de red con la ruta \\nasupv.upv.es\grupos
-
Fuera de la UPV: se accede vía VPN y posteriormente se conecta como una unidad de red con la ruta \\nasupv.upv.es\grupos
-
-
Solicitud/Modificación de grupo de trabajo: debe usarse la aplicación Gregal, indicando el grupo (si ya se conoce) o unas iniciales que lo puedan identificar, una ligera descripción del grupo (si se quiere crear uno nuevo) y los usuarios que deben añadirse o eliminarse del grupo
-
Copia de seguridad automática que permite recuperar los últimos cambios realizados en los ficheros
-
Tanto los datos como la copia de seguridad están en discos ubicados en diferentes edificios de la UPV
-
Cumplimiento con la normativa española de protección de datos (LOPD) y seguridad en los servicios (ENS)
-
Posibilidad de creación de listas de distribución para la comunicación dentro del grupo
OneDrive
-
Posibilidad de que varios investigadores creen un grupo para compartir información
-
Servicio de Microsoft suscrito por la UPV
-
1 TB de almacenamiento por persona, aunque no acepta archivos mayores de 15 GB
-
Acceso desde el portal Office 365
-
Es necesario, en la primera ocasión, solicitar el acceso a Office 365 por la Intranet (Herramientas > Office 365 > Alta del servicio). Una vez aceptadas las condiciones y solicitado el acceso se activará el servicio tras un breve lapso, y permanecerá activo en tanto continúe la relación contractual (profesores, investigadores y PAS) o la matrícula oficial (estudiantes de grado, máster oficial o doctorado)
-
Se pueden seleccionar las carpetas del equipo local que se quieren sincronizar en OneDrive
-
Almacenamiento en la nube en servidores europeos
-
Cumplimiento con la normativa española de protección de datos (LOPD) y seguridad en los servicios (ENS)
Puedes consultar más información sobre los servicios de almacenamiento de datos en la wiki que mantiene el ASIC
Antes de la finalización del proyecto de investigación es muy probable que existan tres tipos de datos:
-
Datos en bruto: datos obtenidos y/o creados durante la investigación
-
Datos procesados: datos extraídos o derivados de los datos en bruto
-
Datos referenciados: subconjunto de los datos procesados que se trabajan para realizar el análisis y extraer conclusiones
-
Verificación de los resultados: los datos se utilizan para facilitar la transparencia y la replicación de la investigación. En este caso, se recomienda preservar tanto los datos procesados como los referenciados
-
Reutilización de los datos: los datos se pueden utilizar en futuras investigaciones, tanto por el mismo investigador como por distintos investigadores. En este caso, se recomienda preservar los datos en bruto
En ambos casos, la documentación que acompaña a los datos debe ser lo suficientemente clara para cumplir con los criterios anteriores
El Digital Curation Center tiene un checklist para ayudar a los investigadores a decidir qué datos deben preservarse, en el que se describen cinco pasos a seguir para facilitar la toma de decisión. Se recomienda que el almacenamiento de los datos para asegurar la preservación se realice:
-
Durante la investigación: en los servicios de almacenamiento que ofrece la UPV
-
Investigación finalizada: en el repositorio de datos adecuado a la investigación
Durante el proceso de investigación es posible que se tenga que trabajar con datos de carácter personal. En estos casos hay varias normas básicas que se deben tener en cuenta:
-
Reglamento (UE) 2016/679 del Parlamento Europeo y del Consejo, de 27 de abril de 2016, relativo a la protección de las personas físicas en lo que respecta al tratamiento de datos personales y a la libre circulación de estos datos (GDPR)
-
Ley Orgánica 3/2018, de 5 de diciembre, de Protección de Datos Personales y garantía de los derechos digitales
-
Guía de buenas prácticas en materia de Transparencia y Protección de Datos. Editado por la CRUE
- Reglamento del Registro de Actividades de Tratamiento de la UPV
Algunos de los principios que rigen estas normas son:
-
Licitud, lealtad y transparencia: los datos deben ser tratados de manera lícita, leal y transparente en relación con el interesado
-
Limitación de la finalidad: los datos deben ser recogidos con fines determinados, explícitos y legítimos
-
Minimización de datos: los datos deben ser adecuados, pertinentes y limitados a lo necesario en relación con los fines para los que son tratados
-
Integridad y confidencialidad: se debe garantizar una seguridad adecuada de los datos personales, incluida la protección contra el tratamiento no autorizado o ilícito y contra su pérdida, destrucción o daño accidental
-
Responsabilidad proactiva: el responsable del tratamiento de los datos será el responsable de cumplir con lo establecido en la legislación y ser capaz de demostrarlo
Teniendo en cuenta estos principios, la protección de los datos personales debe planificarse desde el diseño y por defecto. De hecho, es uno de los apartados que figura en el Plan de Gestión de Datos.
A continuación, se muestra una presentación, realizada dentro del Webinar sobre información legal organizado por OpenAIRE, con consejos prácticos sobre la utilización de datos personales en la investigación en el contexto del GDPR:
Fuente: OpenAIRE. OpenAIRE Legal Policy Webinar: GDPR and Sharing Data ![]()
En la normativa nacional y europea sobre datos personales se nombra explícitamente la seudonimización para tratar datos personales con fines de investigación.
El Reglamento (UE) 2016/679 define la seudonimización como el tratamiento de datos personales de manera tal que ya no puedan atribuirse a un interesado sin utilizar información adicional, siempre que dicha información adicional figure por separado y esté sujeta a medidas técnicas y organizativas destinadas a garantizar que los datos personales no se atribuyan a una persona física identificada o identificable
Hay que señalar las diferencias entre seudonimización y la anonimización:
-
la seudonimización está relacionada con la existencia de una asociación entre identificadores personales y seudónimos, mientras que en la anonimización esa asociación no debería estar disponible en ningún caso
-
la seudonimización permite, si fuera necesario, la reidentificación de las personas por parte del responsable de los datos, mientras que en la anonimización no es posible
-
en la seudonimización se gestionan dos tipos de datos: los seudonimizados y la información adicional que permite la reidentificación de las personas
-
los datos seudonimizados deben ser considerados aún como datos personales mientras que los datos anonimizados no se consideran datos personales
Algunos beneficios de la seudonimización son:
-
Oculta la identidad de las personas mejorando la seguridad y la protección de la privacidad
-
Gestión separada de los datos seudonimizados y la información adicional que permite la reidentificación de las personas y mejora la exactitud de los datos
-
Facilita la minimización de la información almacenada durante el tratamiento de los datos
En diferentes guías se ofrecen técnicas para la seudonimización de los datos:
-
Recommendations on shaping technology according to GDPR provisions: An overview on data pseudonymisation. Editado por la European Union Agency For Network and Information Security
-
Introducción al hash como técnica de seudonimización de datos personales. Editado por la Agencia Española de Protección de Datos
También existen diferentes técnicas para la anonimización de los datos:
-
Orientaciones y garantías en los procedimientos de anonimización de datos personales. Editado por la Agencia Española de Protección de Datos
-
Amnesia: herramienta financiada por OpenAIRE para la anonimización de datos. Utilizando k-anonimización y km anonimización, permite eliminar los identificadores directos (nombre, DNI, etc.) y transforma los identificadores secundarios (fecha de nacimiento, código postal, etc.) de manera que las personas no puedan ser identificadas. Para más información sobre Amnesia, se puede consultar la presentación y el vídeo de un webinar organizado por OpenAIRE en junio 2020

El cifrado hace que los datos personales sean ininteligibles para cualquier persona que no esté autorizada a acceder a ellos
Se recomienda que el almacenamiento de los datos personales se realice en cualquiera de los servicios de almacenamiento para datos que ofrece la UPV. Estos servicios proporcionan control de acceso a los datos, copias de seguridad, etc.
-
Delegación de Protección de Datos (DPD_UPV): es la unidad que tiene encomendadas la supervisión del cumplimiento del Reglamento General de Protección de Datos y de la Ley Orgánica de Protección de Datos Personales y garantía de los derechos digitales en el ámbito de la Universitat Politècnica de València
-
Comité de Ética en Investigación de la UPV: cualquier actividad llevada a cabo en la UPV bien a iniciativa de algún miembro de un Departamento, Instituto, Centro, bien bajo subcontratación o incluso liderada por otras instituciones pero con participación de la UPV y cuya experimentación esté afectada por alguna normativa, por incluir aspectos con implicaciones éticas o de bioseguridad, debe ser previamente autorizada por el Comité de Ética en Investigación de la UPV. Para ello el investigador principal debe seguir el procedimiento y cumplimentar el formulario correspondiente para solicitar la evaluación por parte del comité
Difundir los datos
Muchas agencias de financiación, instituciones y revistas académicas tienen mandatos y políticas sobre la publicación en acceso abierto de los datos de investigación. El cumplimiento de estos mandatos y políticas se suele realizar a través del depósito de los datos de investigación en un repositorio de datos
A la hora de elegir un repositorio hay tener en cuenta algunos aspectos:
-
Área temática
-
Capacidad de almacenamiento
-
Facilidad de recuperación de datos
-
Asignación de un identificador único y persistente para cada conjunto de datos (DOI)
-
Establecimiento de un periodo de embargo para los datos
-
Selección de la licencia de uso de los datos
-
Preservación a largo plazo de los datos
-
Cumplimiento con la certificación CoreTrustSeal
Science Europe ha publicado la Practical Guide to the International Alignment of Research Data donde se explican fácilmente los criterios para seleccionar un repositorio de datos
Según el OpenAIRE Research Data Management Briefing Paper, los datos deben depositarse en un repositorio de datos según el siguiente orden de preferencia:
-
Repositorio temático de datos consolidado para esa disciplina
-
Repositorio institucional de datos
-
Repositorio multidisciplinar de datos
-
Otros repositorios de datos
El Consorci de Serveis Universitaris de Catalunya (CSUC) publicó unas Recomendaciones para seleccionar un repositorio donde depositar datos de investigación, con una tabla comparativa de repositorios
A continuación, se muestran varios repositorios temáticos de datos para algunas disciplinas:
-
Agricultura:
-
Ag Data Commons: amplia variedad de datos abiertos pertinentes para la investigación agrícola
-
-
Biología:
-
BioModels: modelos matemáticos de sistemas biológicos y biomédicos
-
GenBank: secuencias de nucleótidos a disposición del público para casi 260.000 especies formalmente descritas
-
UniProt: recopilación de información funcional sobre las proteínas, con una anotación precisa, consistente y completa
-
Worldwide Protein Data Bank: estructuras tridimensionales de macromoléculas biológicas determinadas experimentalmente
-
-
Ciencias ambientales y de la Tierra:
-
EarthChem: centrado en la preservación, el descubrimiento, el acceso y el análisis de los datos geoquímicos
-
Environmental Data Initiative Repository: datos que proporcionan un contexto para evaluar la naturaleza y el ritmo del cambio ecológico, interpretar sus efectos y prever respuestas biológicas futuras al cambio
-
NERC Earth Observation Data Centre: adquisición, archivo y acceso a los datos de teledetección de la superficie de la Tierra adquiridos por satélite y sensores aerotransportados
-
PANGAEA: archivo, publicación y distribución de datos georeferenciados del sistema terrestre
-
-
Física:
-
HEPData: repositorio para la difusión de datos de la física experimental de partículas
-
-
Materiales:
-
NoMaD Repository: estructura electrónica de los materiales
-
Materials Cloud Archive: ciencia de materiales computacionales
-
-
Química:
-
Cambridge Structural Database (CSD): repositorio para pequeñas moléculas orgánicas y estructuras de cristales metal-orgánicos ofreciendo una representación en 3D
-
PubChem: estructuras químicas, identificadores, propiedades químicas y físicas, actividades biológicas, patentes, salud, seguridad, datos de toxicidad, etc.
-
Strenda DB: datos de enzimas funcionales
-
En Riunet, el repositorio institucional de la UPV, existe la colección Dataset donde se permite el depósito de datos de investigación provenientes de entidades y/o servicios de la UPV, así como proyectos en los que participen investigadores de la UPV
La redacción de un Plan de Gestión de Datos va a permitir planificar las actividades relativas a los datos de investigación durante todas las etapas de su ciclo de vida. Una de estas etapas es el depósito de los datos en un repositorio. En general, se permite el depósito en RiuNet de los datos derivados de investigaciones en las que participan investigadores de la Universitat Politècnica de València
-
Cumplimiento con las políticas y mandatos sobre datos de investigación impuestos por agencias de financiación de la investigación y revistas académicas
-
Asignación de un Digital Object Identifier (DOI) para los datos
-
Presencia de RiuNet en el directorio de repositorios de datos de investigación r3data.org, gracias al cumplimiento de los requisitos para el registro en este directorio
-
Descripción de los datos cumpliendo los estándares internacionales, lo que hace que los datos puedan ser encontrados, accesibles, interoperables y reusables (FAIR)
-
Establecimiento de diferentes tipos de licencias Creative Commons para especificar el uso de los datos
-
Posibilidad de restringir el acceso a los datos durante un tiempo determinado. Durante este periodo de embargo cualquier persona puede solicitar al autor el acceso a los datos a través de la opción “Solicitar una copia al autor”,
-
Almacenamiento y preservación de los datos facilitando su difusión a lo largo del tiempo
Según el OpenAIRE Research Data Management Briefing Paper, los datos deben depositarse preferentemente en un repositorio temático de datos consolidado para esa disciplina. Recursos como re3data.org y FAIRsharing.org permiten localizar repositorios temáticos de datos
Por otra parte, también se debe comprobar la política sobre datos de investigación de la revista donde se publica el trabajo relacionado con los datos que se quieren depositar
En caso de no localizar un repositorio de datos que cumpla con los criterios expresados en los párrafos anteriores, los datos podrán ser depositados en RiuNet
-
Los datos deben haber sido producidos:
-
Dentro de proyectos en los que participen investigadores de la UPV
-
Entidades y/o servicios de la UPV
-
-
Los autores de los datos deben estar en condiciones de conceder los derechos necesarios a la UPV para asegurar la correcta distribución y preservación de los datos a través de RiuNet
-
Si el conjunto de datos contiene datos personales, se debe tener en cuenta lo expresado en la normativa nacional e internacional sobre protección de datos personales
-
Se debe indicar el tipo de versión de los datos que se quiere depositar: datos en bruto, datos procesados, versión final, etc.
-
Los datos deben estar debidamente organizados para facilitar su comprensión y reutilización. Para ello, se seguirán las siguientes recomendaciones:
-
Aunque se pueden depositar varios ficheros con datos de investigación, cada uno de los ficheros no debe superar los 2 GB de tamaño
-
Los investigadores de la UPV podrán realizar el depósito de los datos de investigación en la colección Datasets que se encuentra en RiuNet
-
Si los datos se han obtenido/procesado dentro de un proyecto de investigación con financiación (H2020, MINECO, GVA, etc.) deberá reflejarse en RiuNet durante el depósito, indicando por una parte el agente financiador y por otra el código del proyecto. De esta forma se facilita la justificación del cumplimiento de la política o mandato del agente financiador
-
La fecha de publicación de los datos de investigación deberá introducirse de forma completa, es decir, año/mes/día
-
Los datos depositados deberán cumplir con las condiciones descritas anteriormente. Especialmente, además de los ficheros con los datos se deberá depositar un fichero README.txt donde se describan los datos de investigación
-
La publicación de los datos en RiuNet no es inmediata ya que la biblioteca debe realizar un proceso de validación. Durante este proceso se comprobará el cumplimiento de las condiciones para la aceptación, así como el nivel de descripción de los datos
-
Contacta con la Biblioteca para cualquier duda sobre el depósito de los datos de investigación en RiuNet
Existen múltiples repositorios multidisciplinares de datos, algunos de los más representativos son:
-
Zenodo: repositorio de datos de investigación financiado por el proyecto OpenAIRE que se puede utilizar si no se encuentra ningún repositorio adecuado que encaje con los datos de investigación. Manual de depósito.
-
EUDAT B2SHARE (European Data Infrastructure): proyecto del H2020 que ofrece un repositorio de datos multidisciplinar.
-
Dryad: repositorio multidisciplinar de datos. Tiene costes de depósito del dataset.
- Dataverse: aplicación web de código abierto desarrollada en el marco del proyecto del Institute for Quantitative Social Science (IQSS) y Harvard Library para poner datos de investigación a disposición de investigadores y recolectores de datos en todo el mundo.
-
Figshare: repositorio multidisciplinar de datos.
Además de los repositorios de datos enumerados anteriormente, es posible localizar otros repositorios a través de directorios como re3data.org y FAIRsharing.org
Además de la difusión en Acceso Abierto de los datos de investigación a través de los repositorios, también es posible publicar estos datos en data journals. Estas revistas publican data papers, que son artículos centrados en los datos en sí mismos (descripción, metodología, motivación, etc.) y no en las hipótesis, análisis y conclusiones extraídas a partir de estos datos.
La publicación de los datos de investigación en data journals ofrece múltiples beneficios a los investigadores:
-
Proceso de revisión por pares que garantiza la calidad de los datos
-
Publicación de datos de investigación con un alto potencial de reutilización
-
Facilita la cita y reconocimiento académico
-
Difusión en Acceso Abierto respetando el reconocimiento a los autores
-
Mejora la transparencia en la investigación
-
Asignación de un DOI (Digital Object Identifier) a los datos de investigación
Existen múltiples data journals, tanto disciplinares como multidisciplinares, donde es posible publicar los datos de investigación. La Biblioteca de la Universidade da Coruña y la Biblioteca de la UPV hemos realizado una recopilación con más de 50 data journals. Para cada data journal se ofrece información, entre la que destaca:
-
Temática
-
Saber si está indexada en el Directory of Open Access Journals (DOAJ)
-
Saber si está indexada en las Web of Science Core Collections (WOS)
-
Cuartil que ocupa en el Scimago Journal and Country Rank (SJR)
-
Tipos de trabajos que publica: data papers, software papers, etc.
La Ley de Propiedad Intelectual, que ha sido adaptada a la normativa europea, recoge dos aspectos muy importantes aplicables a los datos de investigación:
-
Son objeto de propiedad intelectual las creaciones originales literarias, artísticas o científicas expresadas por cualquier medio o soporte, tangible o intangible, actualmente conocido o que se invente en el futuro (artículo 10)
-
Las bases de datos donde figuran los datos de investigación sí son objeto de propiedad intelectual (artículo 12) mediante el derecho “sui generis” (título VIII)
El derecho “sui generis” sobre una base de datos tiene las siguientes características:
-
Protege la inversión sustancial, evaluada cualitativa o cuantitativamente, que realiza el fabricante de la base de datos ya sea de medios financieros, empleo de tiempo, esfuerzo, energía u otros de similar naturaleza, para la obtención, verificación o presentación de su contenido
-
El fabricante de una base de datos puede prohibir la extracción y/o reutilización de la totalidad o de una parte sustancial del contenido de la base de datos, evaluada cualitativa o cuantitativamente, siempre que la obtención, la verificación o la presentación de dicho contenido representen una inversión sustancial desde el punto de vista cuantitativo o cualitativo. Este derecho podrá transferirse, cederse o darse en licencia contractual
-
No estarán autorizadas la extracción y/o reutilización repetidas o sistemáticas de partes no sustanciales del contenido de una base de datos que supongan actos contrarios a una explotación normal de dicha base o que causen un perjuicio injustificado a los intereses legítimos del fabricante de la base
-
La protección de las bases de datos se entenderá sin perjuicio de los derechos existentes sobre su contenido
-
El plazo de protección expirará quince años después del 1 de enero del año siguiente a la fecha en que haya terminado el proceso de fabricación de la base de datos. En los casos de bases de datos puestas a disposición del público antes de la expiración del período descrito anteriormente, el plazo de protección expirará a los quince años, contados desde el 1 de enero siguiente a la fecha en que la base de datos hubiese sido puesta a disposición del público por primera vez
A continuación, se muestra una presentación, realizada dentro del Webinar sobre información legal organizado por OpenAIRE, con información práctica sobre la protección de los datos de investigación dentro de la legislación europea:
Fuente: OpenAIRE. OpenAIRE Legal Policy Webinar: Data, Data Ownership and Open Science ![]()
Tal y como se recoge en las Guidelines on Open Access to Scientific Publications and Research Data in Horizon 2020, es conveniente añadir licencias de uso a los sets de datos que se generen
Para indicar el tipo de uso permitido, se pueden utilizar licencias Creative Commons 4.0, como las CC0 y CC-BY. También es posible utilizar licencias específicas para datos Open Data Commons:
-
Attribution License (ODC-By) — “Attribution for data/databases” permite a terceros copiar, distribuir y usar la base de datos, así como utilizarla para crear nuevos contenidos, bases de datos o colecciones de bases de datos (siempre y cuando se cite la base de datos original)
-
Open Database License (ODC-ODbL) — “Attribution Share-Alike for data/databases” permite a terceros copiar, distribuir y usar la base de datos, así como utilizarla para crear nuevos contenidos, bases de datos o colecciones de bases de datos, siempre y cuando que a las bases de datos derivadas se les otorgue la misma licencia que a la base de datos original
Para programas informáticos se recomienda el uso de licencias de la Free Software Foundation y la Open Source Iniciative, que se pueden localizar desde https://tldrlegal.com/
Para la selección de licencias, tanto de datos como de programas informáticos, se recomienda la utilización de la herramienta License selector.
Matriz de compatibilidad de licencias de software libre: documento elaborado por la Oficina de Coordinación de Software Libre de la AMTEGA (Xunta de Galicia), basándose en el trabajo previo hecho por el Centro Nacional de Referencia de Aplicación de las Tecnologías de la Información y Comunicación (CENATIC).
Para complementarlo podéis utilizar el anexo de la Wikipedia para Comparación de licencias de software libre.
No hay que olvidar la idea general “Tan abierto como sea posible, tan cerrado como sea necesario” que se declara en las Guidelines on FAIR Data Management in Horizon 2020. Cumpliendo esta premisa, no se difundirán en abierto los datos de investigación en determinadas situaciones: existencia de cláusulas de confidencialidad, posible explotación comercial o industrial, etc.
La preparación, el almacenamiento y la difusión de los datos de investigación siguiendo los principios FAIR, puede conllevar una serie de costes económicos y en recursos humanos. Sin embargo, existen agencias de financiación que permiten contabilizar estos costes dentro del proyecto de investigación
La Comisión Europea, en el marco del H2020, podrá cubrir costes técnicos y profesionales asociados a la gestión y difusión de los datos de investigación. Para ayudar a contabilizar y justificar estos gastos dentro del proyecto de investigación, se puede utilizar la herramienta de estimación de costes de gestión de datos de investigación desarrollada por OpenAIRE.
A continuación, se muestra una infografía creada por OpenAIRE sobre diferentes aspectos relacionados con los costes de gestión y difusión de los datos de investigación:
También existen otras herramientas para ayudar a contabilizar los diferentes gastos de gestión de datos de investigación, como la Data Management Cost Guide desarrollada por la Universidad de Utrecht
Citar los datos de investigación es una práctica que debe ser realizada por los siguientes motivos:
-
Los datos de investigación deben ser considerados como un output más de la investigación
-
Pueden incorporarse en el CV y en el registro ORCID del investigador
-
Mejoran la transparencia de la investigación
-
Pueden realizarse medidas de impacto de los datos de investigación citados
Para realizar una correcta citación de los datos de investigación se recomienda:
-
Incluir una serie de datos mínimos: Autor, Fecha, Título, Tipo de recurso e Identificador único persistente
-
Identificar unívocamente de los datos de investigación mediante un identificador único persistente (DOI)
-
Citar cada conjunto de datos de forma independiente
-
Utilizar DOI Citation Formatter: servicio que genera las referencias bibliográficas con diferentes estilos de citación a partir del DOI de los datos de investigación
Ejemplos de citas de datos de investigación:
-
Sallstrom, Nathalie; Goulas, Thanos; Martin, Simon; Engstrom, Daniel (2020): Additive Manufacturing of Highly Elastic Nanoclay-crosslinked Hydrogel with Self-healing Abilities. figshare. Dataset. https://doi.org/10.17028/rd.lboro.11793948.v1
-
Herrera, Carlos M. (2019), Complex long-term dynamics of pollinator abundance in undisturbed Mediterranean montane habitats over two decades, v2, Dryad, Dataset, https://doi.org/10.5061/dryad.5hq26p1

Fuente: REBIUN. Cita tus datos de investigación ![]()
Datos de investigación
De una forma sencilla, se puede decir que los datos de investigación son hechos, observaciones o experiencias creados durante el proceso de una investigación. En el documento de buenas prácticas sobre datos de investigación realizado por la FECYT, se recogen cómo pueden ser los datos de investigación:
-
Numéricos, descriptivos o visuales
-
En estado bruto o analizado, pueden ser experimentales u observacionales
-
Incluyen: cuadernos de laboratorio, cuadernos de campo, datos de investigación primaria (incluidos los datos en papel o en soporte informático), cuestionarios, cintas de audio, videos, desarrollo de modelos, fotografías, películas, y las comprobaciones y las respuestas de la prueba, diapositivas, diseños y muestras. En la información sobre la procedencia de los datos también se podría incluir: el cómo, cuándo, donde se recogió y con que (por ejemplo, instrumentos)
-
El código de software utilizado para generar, comentar o analizar los datos también pueden ser considerados datos

Existen numerosas razones para compartir los datos de investigación. En el documento Recomendaciones para la gestión de datos de investigación, elaborado por la red Maredata, se detallan los siguientes motivos:
-
Promover la innovación y la reutilización de los datos que potencialmente puedan tener nuevos usos
-
Facilitar la colaboración entre usuarios de datos, creadores de datos y reutilizadores
-
Maximizar la transparencia y la fiabilidad de los datos
-
Favorecer la reproducibilidad de los ensayos experimentales
-
Permitir la verificación de los resultados de investigación
-
Reducir costes al evitar la duplicación de datos
-
Aumentar el impacto y la visibilidad de la investigación
-
Promover los proyectos de investigación de los que provienen los datos y sus publicaciones
-
Generar un reconocimiento directo de los investigadores productores de datos, como ocurre con cualquier otro resultado de investigación

Fuente: REBIUN. Ciencia Abierta: La investigación y los datos científicos accesibles y abiertos a todos los ciudadanos ![]()
Existen numerosas revistas y agencias de financiación que solicitan que se publiquen los datos de investigación asociados a los trabajos académicos. Sin embargo, es necesario cumplir unos criterios para facilitar que otros investigadores puedan tener acceso a los datos de investigación.
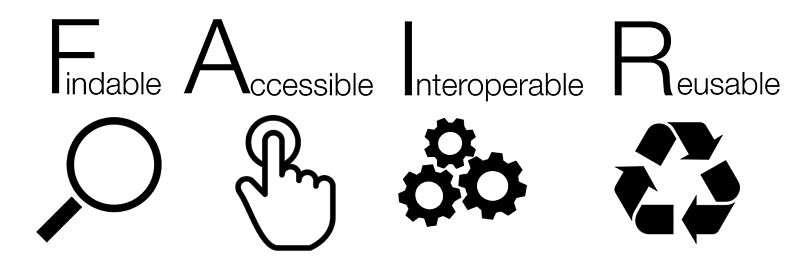
Fuente: Wikipedia Commons ![]()
Los principios FAIR hacen referencia a cómo deben tratarse los datos de investigación para que sean localizables, accesibles, interoperables y reutilizables (Findable, Accessible, Interoperable, Re-usable).

Fuente: Australian National Data Service. FAIR principles ![]()
La herramienta online FAIR-Aware, desarrollada por el proyecto FAIRsFAIR, ayuda a entender mejor los principios FAIR y como contribuyen a mejorar el valor e impacto de los datos de investigación.
Para poder reutilizar los datos de investigación primero hay que localizarlos. Algunos de los principios que se deben cumplir son:
-
Se asignará un identificador único persistente a los datos
-
Se describirán los datos de forma completa usando metadatos
-
Los metadatos podrán ser recuperados o indexados en recursos de búsqueda (por ejemplo, motores de búsqueda) para aumentar su visibilidad
Una vez localizados los datos de investigación, es necesario saber cómo se va a poder acceder a los datos. Algunos de los principios que se deben cumplir son:
-
Se recuperarán los datos mediante su identificador utilizando protocolos de comunicación estandarizados, abiertos e implementables. Estos protocolos permitirán realizar procesos de autenticación y autorización de acceso a los datos
-
Los metadatos estarán accesibles, aunque los datos no estén disponibles
Es necesario que los datos puedan ser interoperables para que sean utilizados por otras aplicaciones o flujos de trabajo. Algunos de los principios que se deben cumplir son:
-
Los metadatos usarán un lenguaje formal, accesible y ampliamente utilizado para la representación del conocimiento
-
Los metadatos mostrarán relaciones descriptivas detalladas entre diferentes recursos
La reutilización de los datos de investigación el objetivo principal que se persigue con los principios FAIR. Algunos de los principios que se deben cumplir son:
-
Los metadatos contendrán un licencia clara y accesible sobre la reutilización de los datos
-
El contenido de los datos (atributos, metodología, variables, software y hardware necesario, etc.) deberá ser descrito para facilitar la reutilización de los datos
Políticas y mandatos
La disponibilidad de los datos de investigación en acceso abierto se está convirtiendo en una recomendación, e incluso obligación, impuesta por las agencias financiadoras de la investigación científica. A través del proyecto Sherpa Juliet se ofrece información sobre estas políticas y mandatos
Desde enero de 2017 todos los proyectos financiados por el programa H2020 (salvo excepciones justificadas) deberán garantizar el acceso abierto a los datos de investigación. Por este motivo, los proyectos participantes en el H2020 han de:
-
Desarrollar y mantener un Plan de Gestión de Datos (Data Management Plan – DMP)
-
Depositar los datos en un repositorio de datos de investigación
En julio de 2021 se publicó el último borrador del “EU Grants Annotated General Model Grant Agreement” para los programas de financiación de la EU para el periodo 2021-2027. En “COMMUNICATION, DISSEMINATION, OPEN SCIENCE AND VISIBILITY” se recogen los siguientes aspectos:
- El acceso abierto ha de ser inmediato, sin embargos, a través de repositorios, bajo una licencia Creative Commons Attribution International (CC BY) o una licencia con derechos equivalentes; y no se reembolsarán los pagos de APCs de publicaciones en revistas híbridas.
- El mandato de acceso abierto se extiende a libros y otras publicaciones de formato extenso, y para monografías y otros formatos de texto largo se permite que la licencia pueda excluir usos comerciales y trabajos derivados (p. ej. CC BY-NC, CC BY-ND).
- Se debe proporcionar información sobre todos los objetos, herramientas e instrumentos académicos que se necesitan para validar las conclusiones de la publicación.
- Los beneficiarios deben gestionar los datos de investigación digitales generados de acuerdo con los principios FAIR, elaborar un plan de gestión de datos y, si es posible, garantizar el acceso abierto a través del repositorio a los datos depositados.
- Se hace referencia a Open Research Europe7, una nueva plataforma de publicación de acceso abierto para los beneficiarios de H2020 / Horizonte Europa.
Cumpliendo la premisa general “Tan abierto como sea posible, tan cerrado como sea necesario”, se persigue que los datos sean localizables, accesibles, interoperables y reutilizables, es decir, que sean FAIR (Findable, Accesible, Interoperable and Reusable)
La Comisión Europea podrá cubrir costes técnicos y profesionales asociados a la gestión y difusión en acceso abierto. Para realizar una estimación de estos costes la Universidad de Utrecht ha creado la Data Management Cost Guide

Fuente: REBIUN. Cómo cumplir con los mandatos sobre gestión y publicación de datos en Horizonte 2020![]()
-
Datos principales (Underlying data): datos necesarios para validar los resultados presentados en publicaciones científicas, incluyendo los metadatos asociados (por ejemplo, los que describen los datos depositados en el repositorio)
-
Cualquier otro dato: por ejemplo, los datos no asociados directamente a una publicación o los datos en bruto, incluyendo los metadatos asociados, dentro de los plazos establecidos en el Plan de Gestión de Datos
Información preliminar sobre la gestión de datos de investigación
En la fase de envío de la documentación para la solicitud de adjudicación del proyecto de investigación, se presenta cierta información que, aunque no es un Plan de Gestión de Datos completo, hace referencia a los datos de investigación que se piensan generar:
-
Qué tipo de datos generará/utilizará el proyecto
-
Qué estándares se usarán
-
Cómo serán los datos utilizados y/o compartidos/accesibles para su verificación y reutilización. Si los datos no estarán accesibles, se debe justificar
-
Cómo serán los datos tratados y preservados
La TU Delft ha creado una guía práctica para ayudar a los investigadores a contestar estas preguntas
Plan de Gestión de Datos
Una vez se ha obtenido la aprobación de la financiación del proyecto y este ha comenzado, se debe enviar la primera versión del Plan de Gestión de Datos (PGD) dentro de los primeros 6 meses del proyecto
El PGD debe ser actualizado durante el proyecto cuando se produzcan cambios significativos, por ejemplo:
-
Nuevos datos
-
Cambios en las políticas: nueva innovación potencial, decisión de solicitar una patente, etc.
-
Cambios en la composición del consorcio y factores externos: nuevos miembros que se incorporan o que abandonan el consorcio
Además, el PGD se debe actualizar en el momento de la evaluación periódica del proyecto, es decir, a mitad y a la finalización del proyecto
Existen varias guías para la elaboración del PGD orientado al ámbito del H2020:
-
Guidelines on FAIR Data Management in Horizon 2020: elaborado por la Comisión Europea, ofrece una completa información sobre los datos de investigación en el H2020 así como una explicación del contenido de cada uno de los apartados del PGD que se debe presentar
-
Plans de Gestió de Dades: creado por el Consorci de Serveis Universitaris de Catalunya (CSUC), sirve como apoyo a los investigadores en la creación de los PGD en el marco del H2020
Se pueden consultar las herramientas y ejemplos para facilitar la creación de un PGD

Fuente: OpenAIRE. https://www.openaire.eu/how-to-comply-to-h2020-mandates-for-data
En cualquier etapa del proyecto de investigación (propuesta, preparación del acuerdo de subvención (GAP) o después de la firma del acuerdo de subvención), es posible declarar de forma justificada la imposibilidad de ofrecer en abierto los datos de investigación
Los motivos que se pueden alegar son los siguientes:
-
Incompatibilidad con la obligación de proteger los resultados si pueden ser explotados comercial o industrialmente
-
Incompatibilidad con temas de confidencialidad o de seguridad
-
Incompatibilidad con regulaciones sobre datos personales
-
Puede poner en peligro el objetivo del proyecto
-
No se generarán o recogerán datos de investigación
-
Cualquier otra razón legítima debidamente justificada
En la convocatoria del año 2020 del procedimiento de concesión de ayudas a "Proyectos de I+D+i" del Plan Estatal de Investigación Científica y Técnica y de Innovación 2017-2020, aparecen por primera vez las siguientes referencias a los datos de investigación:
-
Obligaciones de los beneficiarios (artículo 19.2): los datos de investigación se deberán depositar en repositorios institucionales, nacionales y/o internacionales antes de que transcurran dos años desde la finalización del proyecto, con el fin de impulsar el acceso a datos de investigación de las ayudas financiadas
-
Criterios de evaluación (anexo I, apartado 3): se valorará el plan de publicaciones científico-técnicas, presentaciones y comunicaciones a congresos y otros foros principalmente internacionales; patentes y otros resultados incluidos en la propuesta, y en caso de que resulte pertinente, el plan de gestión de datos de investigación asociados a los resultados
-
Instrucciones para rellenar la memoria científico-técnica (apartado 3.1.b): se debe presentar un Plan de Gestión de Datos de investigación en el cual se muestre la gestión que se aplicará desde su creación hasta la finalización del proyecto de investigación, qué datos se van a recoger o generar, qué metodología y normas se van a emplear, cómo se van a compartir y/o poner en abierto, y cómo se van a conservar y preservar, indicando en qué repositorio de acceso abierto se depositarán
Junto a la convocatoria se ha publicado un documento de preguntas frecuentes. En la pregunta 63 se aclaran varios aspectos relativos a los datos de investigación:
-
No hay que incluir en la solicitud del proyecto el Plan de Gestión de Datos (PGD): en la memoria científico-técnica de la propuesta solamente se deberá incorporar una descripción inicial que contenga qué datos se van a recoger o generar en el marco del proyecto (tipologías y formatos), cómo será el acceso a los mismos (quién, cómo y cuándo se podrá acceder a ellos), de quién son los datos y en qué repositorio está previsto su depósito, difusión y preservación. Así mismo, se recogerán, en su caso, las condiciones éticas o legales específicas que los regulen (ej. privacidad de los datos y su reglamentación; datos protegidos o protegibles por propiedad intelectual o industrial, etc.) que condicionen su disponibilidad, uso y/o reutilización
-
El PGD se deberá presentar, si así es requerido, junto con los informes de seguimiento intermedio y final del proyecto financiado. Así mismo, se recomienda la publicación en acceso abierto del PGD junto a los datasets utilizados, y en formato legible por máquina
-
Se recomienda que todos los datos de investigación resultantes de proyectos financiados con fondos públicos sean siempre FAIR y, siempre que sea posible, abiertos
-
Se han de depositar en repositorios de acceso abierto todos los datos que subyacen a la investigación, esto es, los datos brutos generados o producidos en el transcurso de la investigación
-
Se deberán publicar, junto a los artículos científicos, los datos finales que sean necesarios para garantizar la verificación y reproducibilidad de los resultados presentados
-
En el depósito y publicación de los datos se deberá tener en cuenta: la protección de datos personales, aspectos éticos y los requisitos específicos de las editoriales científicas
En el artículo 5.4 de la Orden CNU/320/2019, de 13 de marzo, se detallan las obligaciones de los beneficiarios de las ayudas públicas en el marco del Plan Estatal:
-
Los datos de investigación deberán estar disponibles en acceso abierto, aunque podrá haber excepciones
-
Las convocatorias podrán prever la realización de un Plan de Gestión de Datos que formará parte de la documentación de la solicitud y que se podrá modificar durante la ejecución del proyecto
-
Si se van a difundir en abierto los datos, se indicará el repositorio institucional o temático de acceso abierto en el que se depositarán los datos
- Las excepciones a la obligatoriedad del acceso abierto a los datos de investigación son:
-
Cuando se prevea que los datos generados en la investigación y los resultados de la investigación realizada puedan ser sometidos a solicitud de la protección de derechos de propiedad industrial o intelectual.
-
Cuando por su naturaleza los datos estén sujetos a la protección de datos de carácter personal o cuando afecten a la seguridad pública.
El Plan Estatal de Investigación Científica y Técnica y de Innovación 2017-2020, a través de las actuaciones que financia, tiene como objetivo promover el acceso abierto a resultados y datos de la investigación, así como impulsar un modelo de investigación responsable y abierta a la sociedad. Se encuentran varias referencias a los datos de investigación:
-
Los proyectos de I+D+i financiados podrán incluir un plan de gestión de los datos de investigación que se depositarán en repositorios institucionales, nacionales y/o internacionales tras la finalización del proyecto y trascurrido el plazo establecido en las correspondientes convocatorias.
-
Se respetarán todas las situaciones en las que los mismos han de protegerse por razones de confidencialidad, seguridad, protección, etc. o cuando los mismos sean necesarios para la explotación comercial de los resultados obtenidos.
-
En la evaluación curricular de los investigadores, así como en la evaluación ex post de las actuaciones financiadas, se tendrán en cuenta los trabajos publicados en abierto en repositorios institucionales y temáticos, nacionales y/o internacionales, y la puesta de los datos de su investigación en abierto, de modo que puedan ser utilizados para replicar y reproducir los análisis y resultados de investigación.
-
Impulso a la adopción de los principios de acceso abierto a los datos de investigación según los principios FAIR.
-
Puesta en marcha de redes de colaboración e investigación científico-técnica que facilite la implantación de un modelo de acceso abierto, de resultados y especialmente datos de investigación.
El marco de referencia plurianual para el fomento de la investigación científica, técnica y de innovación en España es la “Estrategia Española de Ciencia, Tecnología e Innovación (EECTI) 2021-2027".
Diseñada para maximizar la coordinación entre la planificación y programación estatal y autonómica y para facilitar la articulación de la política nacional de I+D+I con el programa marco de ciencia e innovación de la UE.
En el Eje de actuación se recoge la importancia de la implicación ciudadana en la ciencia y la innovación, fomentando la divulgación y la cultura científica, y promoviendo la ciencia abierta e inclusiva. Al igual que indican las directrices de la UE, se impulsa el acceso abierto a los resultados de investigación, de modo que los datos cumplan con los criterios FAIR (localizables, accesibles, interoperables y reutilizables), y se destaca también el papel de los repositorios abiertos.
Cada vez más revistas solicitan que los datos de investigación en los que se basan las publicaciones científicas estén disponibles en acceso abierto a través de repositorios de datos. De esta manera, se consiguen diferentes beneficios, como mejorar el proceso de revisión por pares, facilitar la reproducibilidad de la investigación, etc.
A continuación, se muestran algunas políticas de editoriales académicas referentes los datos de investigación: